| 7. Subtyping and Inheritance in Computational Languages | ||
|---|---|---|
 | Chapter 12. Subtyping and Inheritance |  |
| 7. Subtyping and Inheritance in Computational Languages | ||
|---|---|---|
| | Chapter 12. Subtyping and Inheritance | |
Subtyping and inheritance have been supported in Object-Oriented Programming (OOP), in database languages (such as SQL99), in the XML schema definition language XML Schema, and in other computational languages, in various ways and to different degrees. At its core, subtyping in computational languages is about defining type hierarchies and the inheritance of features: properties, constraints and methods in OOP; table columns and constraints in SQL99; elements, attributes and constraints in XML Schema.
In general, it is desirable to have support for multiple classification and multiple inheritance in type hierarchies. Both language features are closely related and are considered to be advanced features, which may not be needed in many applications or can be dealt with by using workarounds.
Multiple classification means that an object has more than one direct type. This is mainly the case when an object plays multiple roles at the same time, and therefore directly instantiates multiple classes defining these roles.
Multiple inheritance is typically also related to role classes. For instance, a student assistant is a person playing both the role of a student and the role of an academic staff member, so a corresponding OOP class StudentAssistant inherits from both role classes Student and AcademicStaffMember. In a similar way, in our example model above, an AmphibianVehicle inherits from both role classes LandVehicle and WaterVehicle.
The minimum level of support for subtyping in OOP, as provided, for instance, by Java and C#, allows defining inheritance of properties and methods in single-inheritance hierarchies, which can be inspected with the help of an is-instance-of predicate that allows testing if a class is the direct or an indirect type of an object. In addition, it is desirable to be able to inspect inheritance hierarchies with the help of
a predefined instance-level property for retrieving the direct type of an object (or its direct types, if multiple classification is allowed);
a predefined type-level property for retrieving the direct supertype of a type (or its direct supertypes, if multiple inheritance is allowed).
A special case of an OOP language is JavaScript, which did originally not have an explicit language element for defining classes, but only for defining constructor functions. Due to its dynamic programming features, JavaScript allows using various code patterns for implementing classes, subtyping and inheritance. In modern JavaScript, starting from ES2015, defining a superclass and a subclass is straightforward. First, we define a base class, Person, with two properties, firstName and lastName:
class Person { constructor (first, last) { // assign base class properties this.firstName = first; this.lastName = last; } }
Then, we define a subclass, Student, with one additional property, studentNo:
class Student extends Person { constructor (first, last, studNo) { // invoke constructor of superclass super( first, last); // assign additional properties this.studentNo = studNo; } }
Notice how the constructor of the superclass is invoked with super( first, last) for assigning the superclass properties.
In XML Schema, a subtype can be defined by extending or by restricting an existing complex type. While extending a complex type means extending its intension by adding elements or attributes, restricting a complex type means restricting its extension by adding constraints.
We can define a complex type Person and a subtype Student by extending Person in the following way:
<xs:complexType name="Person"> <xs:attribute name="firstName" type="xs:string" /> <xs:attribute name="lastName" type="xs:string" /> <xs:attribute name="gender" type="GenderValue" /> </xs:complexType> <xs:complexType name="Student"> <xs:extension base="Person"> <xs:attribute name="studentNo" type="xs:string" /> </xs:extension> </xs:complexType>
We can define a subtype FemalePerson by restricting Person in the following way:
<xs:complexType name="FemalePerson"> <xs:restriction base="Person"> <xs:attribute name="firstName" type="xs:string" /> <xs:attribute name="lastName" type="xs:string" /> <xs:attribute name="gender" type="GenderValue" use="fixed" value="f" /> </xs:restriction> </xs:complexType>
Notice that by fixing the value of the gender attribute to "f", we define a constraint that is only satisfied by the female instances of Person.
In the Web Ontology Language OWL, property definitions are separated from class definitions and properties are not single-valued, but multi-valued by default. Consequently, standard properties need to be declared as functional. Thus, we obtain the following code for expressing that Person is a class having the property name:
<owl:Class rdf:ID="Person"/> <owl:DatatypeProperty rdf:ID="name"> <rdfs:domain rdf:resource="#Person"/> <rdfs:range rdf:resource="xsd:string"/> <rdf:type rdf:resource="owl:FunctionalProperty"/> </owl:DatatypeProperty>
OWL allows stating that a class is a subclass of another class in the following way:
<owl:Class rdf:ID="Student"> <rdfs:subClassOf rdf:resource="#Person"/> </owl:Class> <owl:DatatypeProperty rdf:ID="studentNo"> <rdfs:domain rdf:resource="#Student"/> <rdfs:range rdf:resource="xsd:string"/> <rdf:type rdf:resource="owl:FunctionalProperty"/> </owl:DatatypeProperty>
For better usability, OWL should allow to define the properties of a class within a class definition, using the case of functional properties as the default case.
A standard DBMS stores information (objects) in the rows of tables, which have been conceived as set-theoretic relations in classical relational database systems. The relational database language SQL is used for defining, populating, updating and querying such databases. But there are also simpler data storage techniques that allow to store data in the form of table rows, but do not support SQL. In particular, key-value storage systems, such as JavaScript's Local Storage API, allow storing a serialization of a JS entity table (a map of entity records) as the string value associated with the table name as a key.
While in the classical version of SQL (SQL92) there is no support for subtyping and inheritance, this has been changed in SQL99. However, the subtyping-related language elements of SQL99 have only been implemented in some DBMS, for instance in the open source DBMS PostgreSQL. As a consequence, for making a design model that can be implemented with various frameworks using various SQL DBMSs (including weaker technologies such as MySQL and SQLite), we cannot use the SQL99 features for subtyping, but have to model inheritance hierarchies in database design models by means of plain tables and foreign key dependencies. This mapping from class hierarchies to relational tables (and back) is the business of Object-Relational-Mapping frameworks such as JPA Providers (like Hibernate), Microsoft's Entity Framework, or the Active Record approach of the Rails framework.
There are essentially three alternative approaches how to represent a class hierarchy with database tables:
Single Table Inheritance (STI) is the simplest approach, where the entire class hierarchy is represented by a single table, containing columns for all attributes of the root class and of all its subclasses, and named after the name of the root class.
Table per Class Inheritance (TCI) is an approach, where each class of the hierarchy is represented by a corresponding table containing also columns for inherited properties, thus repeating the columns of the tables that represent its superclasses.
Joined Tables Inheritance (JTI) is a more logical approach, where each segment subclass is represented by a corresponding table (subtable) connected to the table representing its superclass (supertable) via its primary key referencing the primary key of the supertable, such that the (inherited) properties of the superclass are not represented as columns in subtables.
Notice that the STI approach is closely related to the Class Hierarchy Merge design pattern discussed in Section 6 above. Whenever this design pattern has already been applied in the design model, or the design model has already been re-factored according to this design pattern, the class hierarchies concerned (their subclasses) have been eliminated in the design, and consequently also in the data model to be coded in the form of class definitions in the app's model layer, so there is no need anymore to map class hierarchies to single tables. Otherwise, the design model contains a class hierarchy that is implemented with a corresponding class hierarchy in the app's model layer, which would be mapped to database tables with the help of the STI approach.
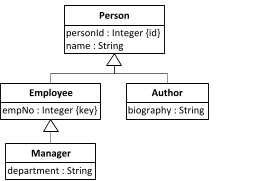
We illustrate the use of these approaches with the help of two simple examples. The first example is the Book class hierarchy, which is shown in Figure 12.1 above. The second example is the class hierarchy of the Person roles Employee, Manager and Author, shown in the class diagram in Figure 12.8 below.
Consider the single-level class hierarchy shown in Figure 12.1 above, which is an incomplete disjoint segmentation of the class Book, as the design for the model classes of an MVC app. In such a case, whenever we have a model class hierarchy with only one level (or only a few levels) of subtyping and each subtype has only a few additional properties, it's preferable to use STI, so we model a single table containing columns for all attributes such that the columns representing additional attributes of segment subclasses ("segment attributes") are optional, as shown in the SQL table model in Figure 12.9 below.
It is a common approach to add a special discriminator column for representing the category of each row corresponding to the subclass instantiated by the represented object. Such a column would normally be string-valued, but constrained to one of the names of the subclasses. If the DBMS supports enumerations, it could also be enumeration-valued. We use the name category for the discriminator column, which, in the case of our Book class hierarchy example, has a frozen value constraint since the textbook-biography segmentation is rigid.
Based on the category of a book, we have to enforce that if and only if it is "TextBook", its attribute subjectArea has a value, and if and only if it is "Biography", its attribute about has a value. This implied constraint is expressed in the invariant box attached to the Book table class in the class diagram above, where the logical operator keyword "IFF" represents the logical equivalence operator "if and only if". It needs to be implemented in the database, e.g., with an SQL table CHECK clause or with SQL triggers.
When the given segmentation is disjoint, a single-valued enumeration attribute category is used for representing the information to which subclass an instance belongs. Otherwise, if it is non-disjoint, a multi-valued enumeration attribute categories is used for representing the information to which subclasses an instance belongs. Such an attribute can be implemented in SQL by defining a string-valued column for representing a set of enumeration codes or labels as corresponding string concatenations.
Consider the class hierarchy shown in Figure 12.8 above. With only three additional attributes defined in the subclasses Employee, Manager and Author, this class hierarchy can again be mapped with the STI approach, as shown in the SQL table model Figure 12.10 below.
Notice that now the discriminator column categories is multi-valued, since the segmentation of Person is not disjoint, but overlapping, implying that a Person object may belong to several categories. Notice also that, since a role segmentation (like Employee, Manager, Author) is not rigid, the discriminator column categories does not have a frozen value constraint.
An example of an admissible population for this model is the following:
| people | |||||
|---|---|---|---|---|---|
| person_id | name | categories | biography | emp_no | department |
| 1001 | Harry Wagner | Author, Employee | Born in Boston, MA, in 1956, ... | 21035 | |
| 1002 | Peter Boss | Manager | 23107 | Sales | |
| 1003 | Tom Daniels | ||||
| 1077 | Immanuel Kant | Author | Immanuel Kant (1724-1804) was a German philosopher ... | ||
Notice that the Person table contains four different types of people:
A person, Harry Wagner, who is both an author (with a biography) and an employee (with an employee number).
A person, Peter Boss, who is a manager (a special type of employee), managing the Sales department.
A person, Tom Daniels, who is neither an author nor an employee.
A person, Immanuel Kant, who is an author (with a biography).
Pros of the STI approach: It leads to a faithful representation of the subtype relationships expressed in the original class hierarchy; in particular, any row representing a subclass instance (an employee, manager or author) also represents a superclass instance (a person).
Cons: (1) In the case of a multi-level class hierarchy where the subclasses have little in common, the STI approach does not lead to a good representation. (2) The structure of the given class hierarchy in terms of its elements (classes) is only implicitly preserved.
In a more realistic model, the subclasses of Person shown in Figure 12.8 above would have many more attributes, so the STI approach would be no longer feasible. In the TCI approach we get the SQL table model shown in Figure 12.11 below. A TCI model represents each concrete class of the class hierarchy as a table, such that each segment subclass is represented by a table that also contains columns for inherited properties, thus repeating the columns of the table that represents the superclass.
A TCI table model can be derived from the information design model by performing the following steps:
Replacing the standard ID property modifier {id} in all classes with {pkey} for indicating that the standard ID property is a primary key.
Replacing the singular (capitalized) class names (Person, Author, etc.) with pluralized lowercase table names (people, authors, etc.), and replacing camel case property names (personId and empNo) with lowercase underscore-separated names for columns (person_id and emp_no).
Adding a «table» stereotype to all class rectangles.
Replacing the platform-independent datatype names with SQL datatype names.
Dropping all generalization/inheritance arrows and adding all columns of supertables (such as person_id and name from people) to their subtables (authors and employees).
Each table would only be populated with rows corresponding to the direct instances of the represented class. An example of an admissible population for this model is the following:
| people | |
|---|---|
| personId | name |
| 1003 | Tom Daniels |
| authors | ||
|---|---|---|
| person_id | name | biography |
| 1001 | Harry Wagner | Born in Boston, MA, in 1956, ... |
| 1077 | Immanuel Kant | Immanuel Kant (1724-1804) was a German philosopher ... |
| employees | ||
|---|---|---|
| person_id | name | emp_no |
| 1001 | Harry Wagner | 21035 |
| managers | |||
|---|---|---|---|
| person_id | name | emp_no | department |
| 1002 | Peter Boss | 23107 | Sales |
Pros of the TCI approach: (1) The structure of the given class hierarchy in terms of its elements (classes) is explicitly preserved. (2) When the segmentations of the given class hierarchy are disjoint, TCI leads to memory-efficient non-redundant storage.
Cons: (1) The TCI approach does not yield a faithful representation of the subtype relationships expressed in the original class hierarchy. In particular, for any row representing a subclass instance (an employee, manager or author) there is no information that it represents a superclass instance (a person). Thus, the TCI database schema does not inform about the represented subtype relationships; rather, this meta-information, which is kept in the app's class model, is de-coupled from the database. (2) The TCI approach requires repeating column definitions, which is a form of schema redundancy. (3) The TCI approach may imply data redundancy whenever the segment subclasses overlap. In our example, authors can also be employees, so for any person in the overlap, we would need to duplicate the data storage for all columns representing properties of the superclass (in our example, this only concerns the property name).
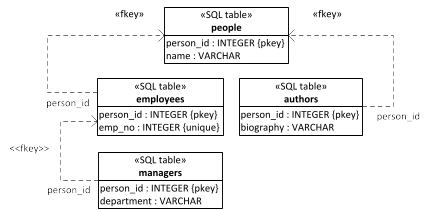
For avoiding the data redundancy problem of TCI in the case of overlapping segmentations, we could take the JTI approach as exemplified in the SQL table model shown in Figure 12.12 below. This model connects tables representing subclasses (subtables) to tables representing their superclasses (supertables) by defining their primary key column(s) to be at the same time a foreign key referencing their supertable's primary key. Notice that foreign keys are visualized in the form of UML dependency arrows stereotyped with «fkey» and annotated at their source table side with the name of the foreign key column.
An example of an admissible population for this model is the following:
| people | |
|---|---|
| person_id | name |
| 1001 | Harry Wagner |
| 1002 | Peter Boss |
| 1003 | Tom Daniels |
| 1077 | Immanuel Kant |
| authors | |
|---|---|
| person_id | biography |
| 1001 | Born in Boston, MA, in 1956, ... |
| 1077 | Immanuel Kant (1724-1804) was a German philosopher ... |
| employees | |||
|---|---|---|---|
| person_id | emp_no | ||
| 1001 | 21035 | ||
| 1002 | 23107 | ||
| managers | |||
|---|---|---|---|
| person_id | department | ||
| 1002 | Sales | ||
Pros of the JTI approach: (1) Subtyping relationships and the structure of class hierarchies are explicitly preserved. (2) Data redundancy in the case of overlapping segmentations is avoided.
Cons: (1) The main disadvantage of the JTI approach is that for querying a subclass, join queries (for joining the segregated entity data) are required, which may create performance issues.
| |  | |
| 6. The Class Hierarchy Merge Design Pattern |  | 8. Quiz Questions |